
Это первая статья из цикла “Разрабатываем свой язык программирования на Java”, который на примере разработки простого языка, покажет полный путь создания языка, а также написания и поддержки инструментов для него. К концу данной статьи реализуем интерпретатор, с помощью которого можно будет выполнять программы на нашем языке.
Любой язык программирования имеет синтаксис, который необходимо преобразовать в удобную для валидации, преобразования и исполнения структуру данных. Как правило, такой структурой данных выступает абстрактное синтаксическое дерево (abstract syntax tree, AST). Каждый узел дерева обозначает конструкцию, встречающуюся в исходном коде. Исходный код разбирается парсером и на выходе получается AST.
Языки разрабатываются давно, и поэтому на текущий момент мы имеем довольно много зрелых инструментов, в том числе генераторы парсеров. Генераторы парсеров на вход принимают описание грамматики конкретного языка, а на выходе получаем парсеры, интерпретаторы и компиляторы.
В данной статье рассмотрим инструмент ANTLR. ANTLR – утилита, на вход которой подается грамматика в виде РБНФ, а на выходе получаем интерфейсы/классы (в нашем случае это java-код) для разбора программ. Список языков, на которых генерируются парсеры, можно найти здесь.
Пример грамматики
Перед тем как перейти к реальной грамматике, попробуем на словах описать некоторые правила типичного языка программирования:
ПЕРЕМЕННАЯ– этоИДЕНТИФИКАТОРЦИФРА– это один из символов0123456789ЧИСЛО– это один или более элементов типаЦИФРАВЫРАЖЕНИЕ– этоЧИСЛОВЫРАЖЕНИЕ– этоПЕРЕМЕННАЯВЫРАЖЕНИЕ– этоВЫРАЖЕНИЕ‘+’ВЫРАЖЕНИЕВЫРАЖЕНИЕ– это ‘(‘ВЫРАЖЕНИЕ’)’
Как видно из данного списка, языковая грамматика – это набор правил, которые могут иметь рекурсивные связи. Каждое правило может ссылаться на себя или на любое другое правило. ANTLR в своем арсенале имеет множество операторов для описания таких правил.
: метка начала правила
; метка конца правила
| оператор альтернативы
.. оператор диапазона
~ отрицание
. любой символ
= присваивание
(...) подправило
(...)* повторение подправила 0 или более раз
(...)+ Повторение подправила 1 или более раз
(...)? подправило, может отсутствовать
{...} семантические действия (на языке, использующемся в качестве выходного – например, Java)
[...] параметры правила
Примеры правил на ANTLR
Следующий пример описывает правила для целых чисел и чисел с плавающей точкой:
NUMBER : [0-9]+ ; FLOAT : NUMBER '.' NUMBER ;
Очень важно понимать, что грамматика описывает только синтаксис языка, на основе которого будет генерироваться парсер. Парсер будет генерировать AST, используя который, можно будет реализовать семантику языка. В предыдущем примере, мы задали правило для разбора целого числа, но не описали какой объем памяти занимает число (8 бит, 16, …), является ли число со знаком или без. Например, в некоторых языках программирования переменную можно начать использовать, не объявив ее. Также можно не объявлять тип переменной, в этом случае тип будет определен автоматически в рантайме. Все эти правила семантики языка не описываются в грамматике, а реализуются в другой части языка.
Лексемы и выражения ANTLR
Грамматика ANTLR состоит из двух типов правил: лексем и выражений, которые используются для определения структуры грамматики и разбора входных данных.
Лексемы (или токены) – это правила, которые определяют отдельные лексические элементы входного языка, такие как числа, идентификаторы, знаки операций и т.д. Каждой лексеме соответствует определенный тип токена, который используется для дальнейшей обработки синтаксическим анализатором. Лексический анализатор сканирует входной текст, разбивает его на лексемы и создает последовательность токенов, которые затем передаются синтаксическому анализатору. Записываются в верхнем регистре (Например: NUMBER, IDENTIFIER).
Выражения – это правила, которые определяют структуру грамматики входного языка. Они описывают, каким образом лексемы связаны между собой и как они могут быть объединены в более сложные конструкции. Выражения могут содержать ссылки на лексемы, а также на другие выражения. Записываются в нотации сamelCase (Например: expression, functionDefinition).
Таким образом, разница между лексемами и выражениями в ANTLR заключается в том, что лексемы определяют отдельные лексические элементы входного языка и преобразуют их в токены, а выражения определяют структуру грамматики и описывают, каким образом лексемы связаны между собой в более сложные конструкции.
Требования к языку
Перед тем как начать реализовывать язык необходимо определиться с набором возможностей, которые он должен поддерживать. Для нашей задачи, в образовательных целях, мы будем использовать простую грамматику. Язык будет поддерживать следующие конструкции:
- Переменные (типов
String,Long,Double); - Оператор присваивания (=);
- Арифметические операции (+, -, *, /);
- Операторы сравнения (>, <, >=, <=, ==, !=);
- Условные операторы (if, else);
- Функции;
- Печать в консоль (встроенный оператор
println).
Грамматика
Ну и наконец, полное описание грамматики для языка:
grammar Jimple;
// корневое правило грамматики
program: (statement)* EOF;
// список возможных утверждений
statement: variableDeclaration
| assignment
| functionDefinition
| functionCall
| println
| return
| ifStatement
| blockStatement
;
// список возможных выражений
expression: '(' expression ')' #parenthesisExpr
| left=expression op=(ASTERISK | SLASH) right=expression #mulDivExpr
| left=expression op=(PLUS | MINUS) right=expression #plusMinusExpr
| left=expression compOperator right=expression #compExpr
| IDENTIFIER #idExp
| NUMBER #numExpr
| DOUBLE_NUMBER #doubleExpr
| STRING_LITERAL #stringExpr
| functionCall #funcCallExpr
;
// описания отдельных выражений и утверждений
variableDeclaration: 'var' IDENTIFIER '=' expression ;
assignment: IDENTIFIER '=' expression ;
compOperator: op=(LESS | LESS_OR_EQUAL | EQUAL | NOT_EQUAL | GREATER | GREATER_OR_EQUAL) ;
println: 'println' expression ;
return: 'return' expression ;
blockStatement: '{' (statement)* '}' ;
functionCall: IDENTIFIER '(' (expression (',' expression)*)? ')' ;
functionDefinition: 'fun' name=IDENTIFIER '(' (IDENTIFIER (',' IDENTIFIER)*)? ')' '{' (statement)* '}' ;
ifStatement: 'if' '(' expression ')' statement elseStatement? ;
elseStatement: 'else' statement ;
// список токенов
IDENTIFIER : [a-zA-Z_] [a-zA-Z_0-9]* ;
NUMBER : [0-9]+ ;
DOUBLE_NUMBER : NUMBER '.' NUMBER ;
STRING_LITERAL : '"' (~["])* '"' ;
ASTERISK : '*' ;
SLASH : '/' ;
PLUS : '+' ;
MINUS : '-' ;
ASSIGN : '=' ;
EQUAL : '==' ;
NOT_EQUAL : '!=' ;
LESS : '<' ;
LESS_OR_EQUAL : '<=' ;
GREATER : '>' ;
GREATER_OR_EQUAL : '>=' ;
SPACE : [ \r\n\t]+ -> skip;
LINE_COMMENT : '//' ~[\n\r]* -> skip;
Как вы уже, наверное, догадались, наш язык называется Jimple (происходит от Jvm Simple). Пожалуй, стоит объяснить некоторые моменты, которые могут быть неочевидными при первом знакомстве с ANTLR.
Метки
При описании правил некоторых операций была использована метка op. Это позволяет нам в дальнейшем использовать эту метку в качестве имени переменной, которая будет содержать значение оператора. В принципе, можно было бы обойтись без указания меток, но в таком случае придется писать дополнительный код, чтобы достать значение оператора из дерева разбора.
compOperator: op=(LESS | LESS_OR_EQUAL | EQUAL | NOT_EQUAL | GREATER | GREATER_OR_EQUAL) ;
Именованные альтернативы правил
В ANTLR при определении правила с несколькими альтернативами каждому из них можно дать имя, и тогда в дереве это будет отдельный узел обработки. Что очень удобно когда нужно вынести обработку каждого варианта правила в отдельный метод. Важно, что наименования нужно задать либо всем альтернативам, либо ни одной из них. Следующий пример демонстрирует, как это выглядит:
expression: '(' expression ')' #parenthesisExpr
| IDENTIFIER #idExp
| NUMBER #numExpr
ANTLR сгенерирует следующий код:
public interface JimpleVisitor<T> {
T visitParenthesisExpr(ParenthesisExprContext ctx);
T visitIdExp(IdExpContext ctx);
T visitNumExpr(NumExprContext ctx);
}
Каналы
В ANTLR существует такая конструкция как канал (channel). Обычно каналы используются для работы с комментариями, но так как в большинстве случаев нам не нужно проверять наличие комментариев их необходимо отбросить с помощью -> skip, чем мы и воспользовались. Однако, бывают случаи, когда нам нужно интерпретировать значение комментариев или других конструкций, тогда вы используете каналы. В ANTLR уже есть встроенный канал под названием HIDDEN, который вы можете использовать, или объявить свои каналы для определенных целей. Далее при разборе кода можно будет получить доступ к этим каналам.
Пример объявления и использования канала
channels { MYLINECOMMENT }
LINE_COMMENT : '//' ~[rn]+ -> channel(MYLINECOMMENT) ;
Фрагменты
На ряду с токенами (лексемами) в ANTLR присутствует такое понятие как фрагменты (fragment). Правила с префиксом фрагмента могут быть вызваны только из других правил лексера. Они не являются токенами сами по себе. В следующем примере мы вынесли во фрагменты определения чисел для разных систем счисления.
NUMBER: DIGITS | OCTAL_DIGITS | HEX_DIGITS;
fragment DIGITS: '1'..'9' '0'..'9'*;
fragment OCTAL_DIGITS: '0' '0'..'7'+;
fragment HEX_DIGITS: '0x' ('0'..'9' | 'a'..'f' | 'A'..'F')+;
Таким образом, число в любой системе счисления (например: «123», «0762» или «0xac1») будет рассматриваться как токен NUMBER, а не DIGITS, OCTAL_DIGITS или HEX_DIGITS. В Jimple фрагменты не используются.
Инструменты
Перед тем как приступить к генерации парсера, нам нужно настроить инструменты для работы с ANTLR. Как известно, хороший и удобный инструмент — это половина успеха. Для этого нам понадобится скачать ANTLR библиотеку и написать скрипты для его запуска. Существуют также maven/gradle/IntelliJ IDEA плагины, которые мы не будем использовать в этой статье, но для продуктивной разработки они могут быть полезны.
Нам понадобятся следующие скрипты:
Скрипт antlr4.sh
java -Xmx500M -cp ".:/usr/lib/antlr-4.12.0-complete.jar" org.antlr.v4.Tool $@
Скрипт grun.sh
java -Xmx500M -cp ".:/usr/lib/antlr-4.12.0-complete.jar" org.antlr.v4.gui.TestRig $@
Генерация парсера
Сохраните грамматику в файле Jimple.g4. Далее запустите скрипт следующим образом:
antlr4.sh Jimple.g4 -package org.jimple.lang -visitor
Параметр -package позволяет указать java package, в котором будет сгенерирован код. Параметр -visitor позволяет сгенерировать интерфейс JimpleVisitor, который реализует паттерн Visitor.
После успешного выполнения скрипта в текущей директории появятся несколько файлов: JimpleParser.java, JimpleLexer.java, JimpleListener.java, JimpleVisitor.java. Первые два файла содержат сгенерированный код парсера и лексера соответственно. Остальные два файла содержат интерфейсы для работы с деревом разбора. В этой статье мы будем использовать интерфейс JimpleVisitor, а точнее JimpleBaseVisitor — это также сгенерированный класс, который реализует интерфейс JimpleVisitor и содержит реализации всех методов. Это позволяет переопределить только те методы, которые нам нужны.
Реализация интерпретатора
Наконец-то мы добрались до самого интересного — реализации интерпретатора. Хотя в данной статье не будем затрагивать вопрос проверки кода на ошибки, но ошибки интерпретации все-таки будут реализованы. Для начала, создадим класс JimpleInterpreter с методом eval, на вход которого будет подаваться строка с кодом на Jimple. Далее нам нужно разобрать исходный код на токены с помощью JimpleLexer, затем создать дерево AST, используя JimpleParser.
public class JimpleInterpreter {
public Object eval(final String input) {
// разбираем исходный код на токены
final JimpleLexer lexer = new JimpleLexer(CharStreams.fromString(input));
// создаем дерево AST
final JimpleParser parser = new JimpleParser(new CommonTokenStream(lexer));
// создаем объект класса JimpleInterpreterVisitor
final JimpleInterpreterVisitor interpreterVisitor = new JimpleInterpreterVisitor(new JimpleContextImpl(stdout));
// запускаем интерпретатор
return interpreterVisitor.visitProgram(parser.program());
}
}
У нас есть синтаксическое дерево. Давайте добавим семантики с помощью написанного нами класса JimpleInterpreterVisitor, который будет обходить AST, вызывая соответствующие методы. Так как корневым правилом нашей грамматики является правило program (см. выше program: (statement)* EOF), то обход дерева начинается именно с него. Для этого вызываем реализованный по умолчанию метод visitProgram у объекта JimpleInterpreterVisitor, на вход которого даем объект класса ProgramContext. Реализация ANTLR состоит из вызова метода visitChildren(RuleNode node), который обходит все дочерние элементы заданного узла дерева, вызывая для каждого из них метод visit.
// код сгенерирован ANTLR
public class JimpleBaseVisitor<T> extends AbstractParseTreeVisitor<T> implements JimpleVisitor<T> {
@Override public T visitProgram(JimpleParser.ProgramContext ctx) {
return visitChildren(ctx);
}
// другие методы опущены для краткости
}
Как можно заметить, JimpleBaseVisitor — это generic-класс, для которого нужно определить тип обработки каждого узла. В нашем случае это класс Object, так как выражения могут возвращать значения разного типа. Обычно выражение (expression) должно вернуть какое-либо значение, а утверждение (statement) ничего не возвращает. В этом и заключается их различие. В случае утверждения можем возвращать null. Однако, чтобы случайно не столкнуться с NullPointerException, вместо null будем возвращать объект типа Object, который глобально определен в классе JimpleInterpreter:
public static final Object VOID = new Object();
Класс JimpleInterpreterVisitor расширяет класс JimpleBaseVisitor, переопределяя только интересующие нас методы. Рассмотрим реализацию встроенного оператора println, который в грамматике описан как println: 'println' expression ;. Первое, что нужно сделать — это вычислить выражение expression, для этого нам нужно вызвать метод visit и передать в него объект expression из текущего контекста PrintlnContext. В методе visitPrintln нас совершенно не интересует, как вычисляется выражение, за вычисление каждого правила (контекста) отвечает соответствующий метод. Например, для вычисления строкового литерала используется метод visitStringExpr.
public class JimpleInterpreterVisitor extends JimpleBaseVisitor<Object> {
@Override
public Object visitPrintln(final JimpleParser.PrintlnContext ctx) {
final Object result = visit(ctx.expression());
System.out.println(result);
return null;
}
@Override
public Object visitStringExpr(final JimpleParser.StringExprContext ctx) {
// возвращаем строковый литерал
return cleanStringLiteral(ctx.STRING_LITERAL().getText());
}
private String cleanStringLiteral(final String literal) {
// очистить строку от кавычек
return literal.length() > 1 ? literal.substring(1, literal.length() - 1) : literal;
}
// другие методы опущены для краткости
}
Реализовав только лишь эти методы, интерпретатор уже поддерживает println и строковые литералы, что позволяет нам выполнить код println "Hello, Jimple!".
Запуск интерпретатора
Для запуска интерпретатора нужно создать стандартный метод main, который после небольших проверок, используя класс JimpleInterpreter, будет запускать наш код:
public class MainApp {
public static void main(String[] args) {
if (args.length < 1) {
System.out.println("usage: jimple input.jimple");
System.exit(1);
}
Path path = Paths.get(args[0]);
if (!Files.exists(path)) {
System.err.println("File not found: " + path);
System.exit(1);
}
new JimpleInterpreter().eval(path);
}
}
Детали реализации
Приводить весь код реализации интерпретатора нет необходимости, ссылку на исходники можно будет найти в конце статьи. Однако хочу остановиться на некоторых интересных деталях.
Как уже было упомянуто, интерпретатор построен на основе паттерна Visitor, который посещает узлы дерева AST и выполняет соответствующие инструкции. В процессе выполнения кода в текущем контексте появляются новые идентификаторы (имена переменных и/или функций), которые нужно где-то хранить. Для этого напишем класс JimpleContext, который будет хранить не только эти идентификаторы, но и текущий контекст выполнения вложенных блоков кода и функций, так как локальная переменная и/или параметр функции должны быть удалены после выхода из области их видимости.
@Override
public Object handleFunc(FunctionSignature func, List<String> parameters, List<Object> arguments, FunctionDefinitionContext ctx) {
Map<String, Object> variables = new HashMap<>(parameters.size());
for (int i = 0; i < parameters.size(); i++) {
variables.put(parameters.get(i), arguments.get(i));
}
// создаем новую область видимости параметров функции и помещаем ее в стек
context.pushCallScope(variables);
// выполнение выражений функций опущены для краткости
// удаляем область видимости параметров функции из стека
context.popCallScope();
return functionResult;
}
В нашем языке переменная хранит значение типа, который определяется во время выполнения. Далее, в следующих инструкциях, этот тип может меняться. По сути, у нас получился язык с динамической типизацией. Однако, некоторая проверка типов все же присутствует, в случаях когда, выполнение операции бессмысленно. Например, число нельзя поделить на строку.
Зачем нужно два прохода?
Первоначальная версия интерпретатора заключалась в реализации метода для каждого правила. Например, если метод обработки объявления функции находит функцию с таким именем (и количеством параметров) в текущем контексте, то выбрасывается исключение, иначе функция добавляется в текущий контекст. Таким же образом работает метод вызова функции. Если функция не найдена, то выбрасывается исключение, иначе функция вызывается. Такой подход работает, но он не позволяет вызывать функцию до её определения. Например, следующий код не будет работать:
var result = 9 + 10
println "Result is " + add(result, 34)
fun add(a, b) {
return a + b
}
В данном случае, у нас есть два подхода. Первый — это требовать определять функции до её использования (не очень удобно для пользователей языка). Второй — выполнять два прохода. Первый проход нужен для того, чтобы найти все функции, которые были определены в коде. А второй — непосредственно для выполнения кода. В своей реализации выбрал второй подход. Следует перенести реализацию метода visitFunctionDefinition в отдельный класс, который расширяет уже известный нам сгенерированный класс JimpleBaseVisitor<T>.
// класс находит все функции в коде и регистрирует их в контексте
public class FunctionDefinitionVisitor extends JimpleBaseVisitor<Object> {
private final JimpleContext context;
private final FunctionCallHandler handler;
public FunctionDefinitionVisitor(final JimpleContext context, final FunctionCallHandler handler) {
this.context = context;
this.handler = handler;
}
@Override
public Object visitFunctionDefinition(final JimpleParser.FunctionDefinitionContext ctx) {
final String name = ctx.name.getText();
final List<String> parameters = ctx.IDENTIFIER().stream().skip(1).map(ParseTree::getText).toList();
final var funcSig = new FunctionSignature(name, parameters.size());
context.registerFunction(funcSig, (func, args) -> handler.handleFunc(func, parameters, args, ctx));
return VOID;
}
}
Теперь у нас есть класс, который можем использовать перед непосредственным запуском класса интерпретатора. Он будет наполнять наш контекст определениями всех функций, которые будем вызывать в классе интерпретатора.
Как выглядит AST?
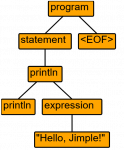
Для того, чтобы визуализировать AST, нужно воспользоваться утилитой grun (см. выше). Для этого следует запустить grun с параметрами Jimple program -gui (первый параметр – имя грамматики, второй – имя правила). В результате откроется окно с деревом AST. Перед выполнением этой утилиты важно скомпилировать сгенерированный ANTLR-ом код.
# сгенерировать парсер antlr4.sh Jimple.g4 # скомпилировать сгенерированный код javac -cp ".:/usr/lib/jvm/antlr-4.12.0-complete.jar" Jimple*.java # запустить grun grun.sh Jimple program -gui # ввести код: "println "Hello, Jimple!" # нажать Ctrl+D (Linux) или Ctrl+Z (Windows)
Для Jimple-кода println "Hello, Jimple!" сгенерируется следующее AST:

Резюме
В данной статье, вы познакомились с таким понятиями как лексический и синтаксический анализаторы. Использовали инструмент ANTLR для генерации таких анализаторов. Узнали, как писать грамматику ANTLR. В итоге смогли создать простой язык, а именно разработали интерпретатор для него. В качестве бонуса смогли визуализировать AST.
Весь исходный код интерпретатора можно посмотреть по ссылке.


